
머신러닝 개요 (Overview)
19 Feb 2020 | Machine-Learning
Machine Learning
머신러닝(Machine Learning, 기계 학습)이란 무엇일까요? ‘머신러닝’이란 용어를 대중화시킨 아서 사무엘(Arthur Samuel)은 다음과 같은 말을 남겼습니다.
“명시적인 프로그래밍 없이 컴퓨터가 학습하는 능력을 갖추게 하는 연구 분야다.” - Arthur Samuel, 1959
코딩 테스트 같은 알고리즘 문제를 풀 때는 주어진 문제의 규칙을 보고 직접 알고리즘을 구현합니다. 머신러닝은 이와 반대로 컴퓨터에게 수많은 케이스를 주어주고 학습시킨 뒤 이 케이스를 만하는 알고리즘을 구현하도록 합니다. 카네기 멜론 대학의 교수이자 머신러닝 학부장인 톰 미첼은 머신러닝에 대해 다음과 같은 말을 남겼습니다. 이 인용문은 머신러닝이 어떤 방식으로 이루어지는 지를 잘 알려줍니다.
“어떤 작업 T에 대한 컴퓨터 프로그램의 성능을 P로 측정했을 때 경험 E로 인해 성능이 향상됐다면, 이 컴퓨터 프로그램은 작업 T와 성능 측정 P에 대해 경험 E로 학습한 것이다.” - Tom Michell, 1997
왜 머신러닝을 사용할까요? 사람이 알고리즘을 구현하는 전통적인 방법론으로는 복잡한 문제를 풀기가 너무 어렵습니다. 예를 들어, 스팸 메일을 분류하는 알고리즘을 사람이 구현한다고 해봅시다. 이런 복잡한 문제는 고려해야 할 사항이 너무 많기 때문에 많은 사람이 긴 코드를 작성해야 합니다. 게다가 코드에서 논리적인 오류가 발견되었을 경우에는 많은 부분을 하하나 직접 수정해주어야 합니다.
같은 문제에 머신러닝 기법을 적용하면 일단 프로그램 코드가 매우 짧아집니다. 어떤 사항을 고려해야 할 지를 기계가 알아서 판단하기 때문입니다. 기존 프로그램과 맞지 않는 데이터가 새로 발견되더라도 특별한 유지보수 없이 다시 기계에게 학습시켜 프로그램을 개선할 수 있습니다. 게다가 이런 문제에 대해서는 머신러닝 방법론을 적용했을 때의 성능(정확도 등)이 더 좋습니다.
Supervised, Unsupervised, Reinforcement
학습의 기준을 어떤 것으로 하는 지에 대해서 지도 학습(Supervised learning)과 비지도 학습(Unsupervised learning), 강화 학습(Reinforcement learning) 으로 나눌 수 있습니다.
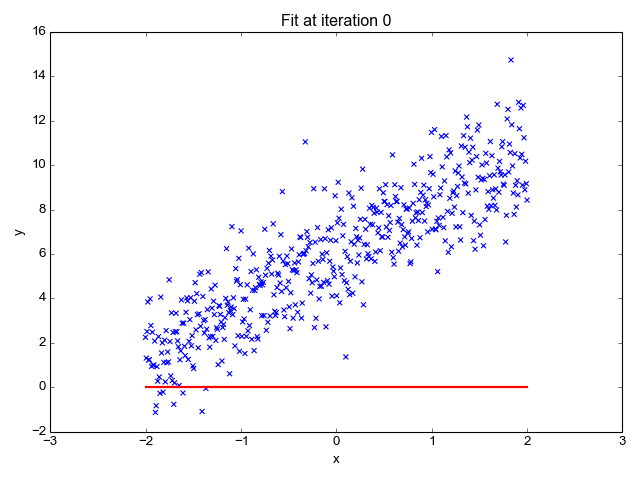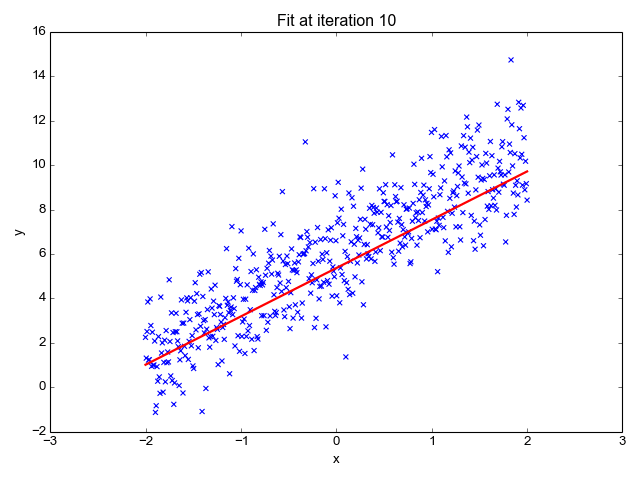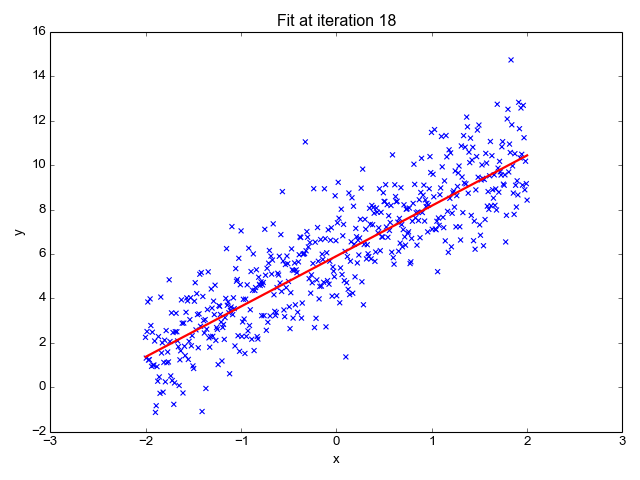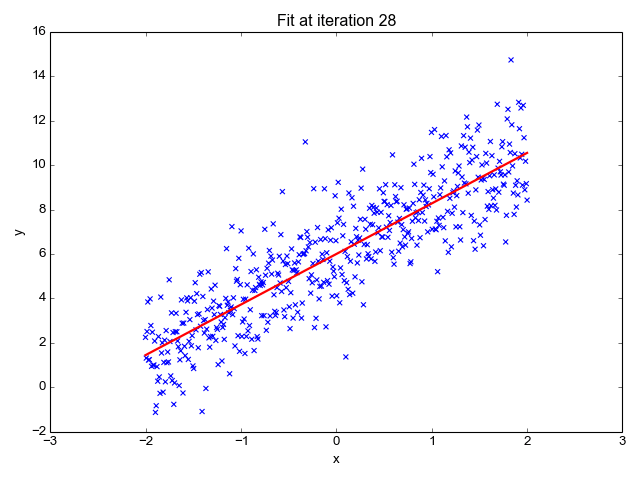
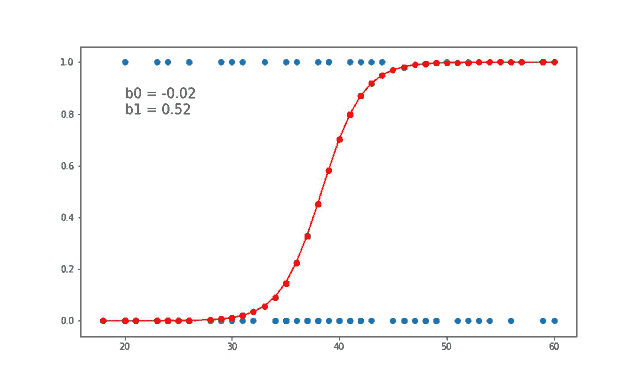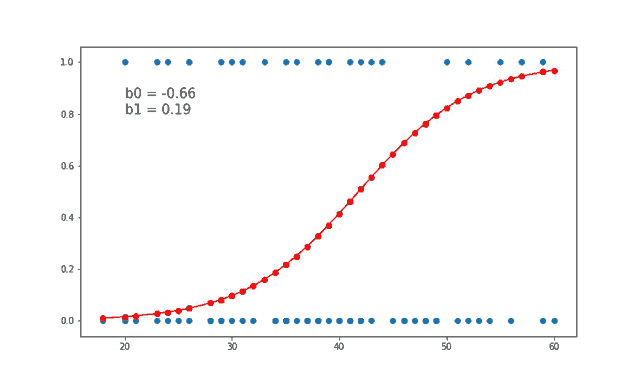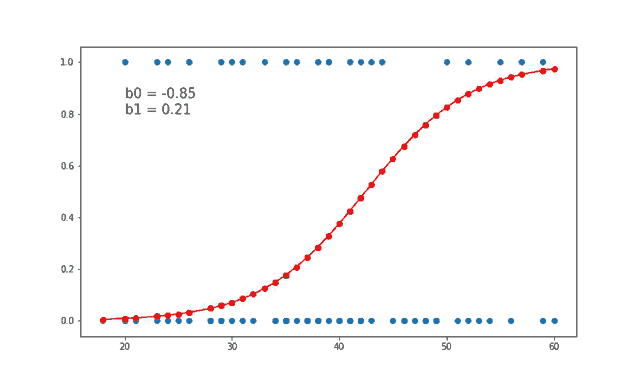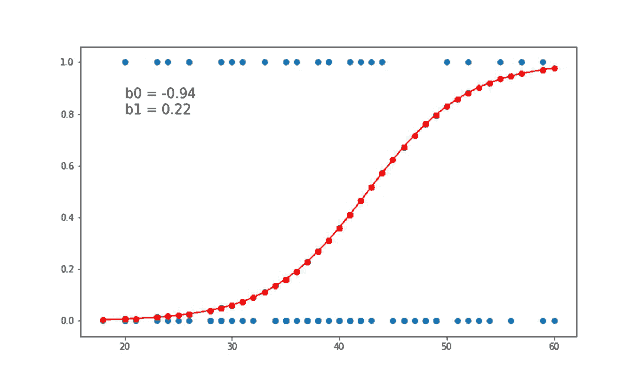
먼저 지도 학습부터 보겠습니다. 지도 학습은 레이블(Label)이 포함되어 있는 훈련 데이터로 학습하는 방법입니다. 답이 있는 데이터셋을 보고 그 답을 맞추는 알고리즘을 기계가 만들어내게 됩니다. 현재 연구가 되어 있는 많은 방법이 지도 학습 방법에 기초하고 있습니다. 크게는 분류(Classification) 와 회귀(Regression) 등으로 나눌 수 있습니다. 다음은 지도 학습에 속하는 알고리즘의 예시입니다.
- k-최근접 이웃(k-nearest neighbors, kNN)
이미지 출처 : machinelearningknowledge.ai
이미지 출처 : primo.ai
이미지 출처 : towardsdatascience.com

이미지 출처 : jeremykun.com

이미지 출처 : algobeans.com
다음은 비지도 학습입니다. 비지도 학습은 레이블 없이 모든 것을 기계의 판단하에 처리하는 알고리즘입니다. 크게는 군집(Clustering), 시각화(Visualization)와 차원 축소(Dimensionality reduction), 연관 규칙 학습(Association rule learning) 등으로 나눌 수 있으며 사용되는 알고리즘으로는 다음과 같은 것들이 있습니다.
- 군집
- k-평균(k-Means)
- 계층 군집 분석(Hierarchical cluster analysis, HCA)
- 기댓값 최대화(Expectation maximization)

이미지 출처 : 위키피디아 - K-means
- 시각화 및 차원축소
- 주성분 분석(Principle component analysis, PCA), 커널 PCA(kernal PCA)
- 지역적 선형 임베딩(Locally-Linear Embedding, LLE), t-SNE(t-distributed Stochastic Neighbor Embedding) 등이 있습니다.

이미지 출처 : ai.googleblog.com
- 연관 규칙 학습
- 아프리오리(Apriori), 이클렛(Eclat)

이미지 출처 : algobeans.com
지도 학습과 비지도 학습 방법을 혼용하는 준지도 학습(Semi-supervised learning)도 있습니다. 이 경우에는 데이터의 일부에만 레이블을 주어주고 나머지 레이블은 기계가 채운뒤 재학습 하도록 합니다. 준지도 학습 알고리즘의 예시로는 심층 신뢰 신경망(Deep belief network, DBN)이 있습니다. 이 방법은 여러 겹으로 쌓은 제한된 볼츠만 머신(Restricted Boltzmann machine, RBM)이라고 불리는 비지도 학습에 기초하고 있습니다.
마지막은 강화 학습입니다. 강화 학습은 지도 학습이나 비지도 학습과는 다른 방식으로 학습이 진행됩니다. 강화 학습에서 학습하는 시스템은 에이전트(Agent)라고 불립니다. 이 에이전트는 현재 상태(State)에서 주변 환경을 관찰하여 행동(Action)을 실행하고 그 결과로 보상(Reward) 혹은 벌점(Panelty)를 받습니다. 같은 작업을 계속 반복하면서 가장 큰 보상을 얻기 위한 최상의 전략을 스스로 학습하게 됩니다.

이미지 출처 : openai.com
Batch vs Online
데이터셋을 학습시키는 방법에 따라 분류하기도 합니다. 배치(Batch) 학습과 온라인(Online) 학습으로 나누기도 합니다. 배치 학습은 학습시킬 데이터를 미리 준비한 뒤에 준비한 데이터를 학습시키는 방법입니다. 방법이 간단하다는 장점이 있지만 시스템이 빠르게 변화해야 하는 상황인 경우에는 사용하기 힘들다는 단점이 있습니다. 그리고 너무 학습 데이터가 너무 방대한 경우에는 시간이 지연되는 문제가 있기 때문에 점진적으로 학습하는 알고리즘을 사용합니다.
온라인 학습은 데이터를 미니 배치(Mini batch)라고 부르는 작은 단위로 묶은 뒤 이 데이터 셋을 학습시킵니다. 커다란 데이터셋을 다룰 수 있다는 장점이 있습니다.
Problems
다음은 머신러닝에서 발생하는 주요한 문제입니다. 머신러닝의 문제점 중 가장 많은 부분을 차지하는 것은 훈련 데이터입니다. 많은 데이터셋에 대하여 훈련 데이터의 양이 충분하지 않거나 대표성이 없고, 낮은 품질의 데이터인 경우가 많습니다. 또한 데이터셋 내에 관련 없는 특성이 많아 희소(Sparsity) 문제가 발생하기도 합니다.
과적합(Overfitting, 과대적합)과 과소적합(Underfitting)의 발생도 주요한 문제입니다. 과적합은 생성한 모델이 훈련 데이터에 너무 잘 맞아버려 일반화(Generalization)되지 않는 현상입니다. 과적합 문제를 해결하기 위해서는 파라미터가 적은 모델을 선택하기, 훈련 데이터에 있는 특성 수를 축소하기, 모델에 규제 적용하기 등의 방법을 통해 단순한 모델을 생성합니다. 과소적합은 너무 단순한 모델이 생성되어 데이터에 잘 맞지 않는 현상입니다. 과소적합 문제를 해결하기 위해서 파라미터가 많은 모델을 선택하거나 학습 알고리즘에 더 좋은 특성을 제공하고 모델의 제약을 줄임으로써 복잡한 모델을 생성합니다. 아래는 이미지의 왼쪽은 과소적합, 오른쪽은 과적합이 발생한 경우를 그림으로 나타낸 것입니다.

이미지 출처 : educative.io
과적합과 과소적합에 대한 추가적인 정보는 과적합과 과소적합 (Overfitting & Underfitting)에서 볼 수 있습니다.
Machine Learning
머신러닝(Machine Learning, 기계 학습)이란 무엇일까요? ‘머신러닝’이란 용어를 대중화시킨 아서 사무엘(Arthur Samuel)은 다음과 같은 말을 남겼습니다.
“명시적인 프로그래밍 없이 컴퓨터가 학습하는 능력을 갖추게 하는 연구 분야다.” - Arthur Samuel, 1959
코딩 테스트 같은 알고리즘 문제를 풀 때는 주어진 문제의 규칙을 보고 직접 알고리즘을 구현합니다. 머신러닝은 이와 반대로 컴퓨터에게 수많은 케이스를 주어주고 학습시킨 뒤 이 케이스를 만하는 알고리즘을 구현하도록 합니다. 카네기 멜론 대학의 교수이자 머신러닝 학부장인 톰 미첼은 머신러닝에 대해 다음과 같은 말을 남겼습니다. 이 인용문은 머신러닝이 어떤 방식으로 이루어지는 지를 잘 알려줍니다.
“어떤 작업 T에 대한 컴퓨터 프로그램의 성능을 P로 측정했을 때 경험 E로 인해 성능이 향상됐다면, 이 컴퓨터 프로그램은 작업 T와 성능 측정 P에 대해 경험 E로 학습한 것이다.” - Tom Michell, 1997
왜 머신러닝을 사용할까요? 사람이 알고리즘을 구현하는 전통적인 방법론으로는 복잡한 문제를 풀기가 너무 어렵습니다. 예를 들어, 스팸 메일을 분류하는 알고리즘을 사람이 구현한다고 해봅시다. 이런 복잡한 문제는 고려해야 할 사항이 너무 많기 때문에 많은 사람이 긴 코드를 작성해야 합니다. 게다가 코드에서 논리적인 오류가 발견되었을 경우에는 많은 부분을 하하나 직접 수정해주어야 합니다.
같은 문제에 머신러닝 기법을 적용하면 일단 프로그램 코드가 매우 짧아집니다. 어떤 사항을 고려해야 할 지를 기계가 알아서 판단하기 때문입니다. 기존 프로그램과 맞지 않는 데이터가 새로 발견되더라도 특별한 유지보수 없이 다시 기계에게 학습시켜 프로그램을 개선할 수 있습니다. 게다가 이런 문제에 대해서는 머신러닝 방법론을 적용했을 때의 성능(정확도 등)이 더 좋습니다.
Supervised, Unsupervised, Reinforcement
학습의 기준을 어떤 것으로 하는 지에 대해서 지도 학습(Supervised learning)과 비지도 학습(Unsupervised learning), 강화 학습(Reinforcement learning) 으로 나눌 수 있습니다.
먼저 지도 학습부터 보겠습니다. 지도 학습은 레이블(Label)이 포함되어 있는 훈련 데이터로 학습하는 방법입니다. 답이 있는 데이터셋을 보고 그 답을 맞추는 알고리즘을 기계가 만들어내게 됩니다. 현재 연구가 되어 있는 많은 방법이 지도 학습 방법에 기초하고 있습니다. 크게는 분류(Classification) 와 회귀(Regression) 등으로 나눌 수 있습니다. 다음은 지도 학습에 속하는 알고리즘의 예시입니다.
- k-최근접 이웃(k-nearest neighbors, kNN)
이미지 출처 : machinelearningknowledge.ai
이미지 출처 : primo.ai
이미지 출처 : towardsdatascience.com
이미지 출처 : jeremykun.com
이미지 출처 : algobeans.com
다음은 비지도 학습입니다. 비지도 학습은 레이블 없이 모든 것을 기계의 판단하에 처리하는 알고리즘입니다. 크게는 군집(Clustering), 시각화(Visualization)와 차원 축소(Dimensionality reduction), 연관 규칙 학습(Association rule learning) 등으로 나눌 수 있으며 사용되는 알고리즘으로는 다음과 같은 것들이 있습니다.
- 군집
- k-평균(k-Means)
- 계층 군집 분석(Hierarchical cluster analysis, HCA)
- 기댓값 최대화(Expectation maximization)
이미지 출처 : 위키피디아 - K-means
{kind=link}
- 시각화 및 차원축소
- 주성분 분석(Principle component analysis, PCA), 커널 PCA(kernal PCA)
- 지역적 선형 임베딩(Locally-Linear Embedding, LLE), t-SNE(t-distributed Stochastic Neighbor Embedding) 등이 있습니다.
이미지 출처 : ai.googleblog.com
- 연관 규칙 학습
- 아프리오리(Apriori), 이클렛(Eclat)
이미지 출처 : algobeans.com
지도 학습과 비지도 학습 방법을 혼용하는 준지도 학습(Semi-supervised learning)도 있습니다. 이 경우에는 데이터의 일부에만 레이블을 주어주고 나머지 레이블은 기계가 채운뒤 재학습 하도록 합니다. 준지도 학습 알고리즘의 예시로는 심층 신뢰 신경망(Deep belief network, DBN)이 있습니다. 이 방법은 여러 겹으로 쌓은 제한된 볼츠만 머신(Restricted Boltzmann machine, RBM)이라고 불리는 비지도 학습에 기초하고 있습니다.
마지막은 강화 학습입니다. 강화 학습은 지도 학습이나 비지도 학습과는 다른 방식으로 학습이 진행됩니다. 강화 학습에서 학습하는 시스템은 에이전트(Agent)라고 불립니다. 이 에이전트는 현재 상태(State)에서 주변 환경을 관찰하여 행동(Action)을 실행하고 그 결과로 보상(Reward) 혹은 벌점(Panelty)를 받습니다. 같은 작업을 계속 반복하면서 가장 큰 보상을 얻기 위한 최상의 전략을 스스로 학습하게 됩니다.
이미지 출처 : openai.com
Batch vs Online
데이터셋을 학습시키는 방법에 따라 분류하기도 합니다. 배치(Batch) 학습과 온라인(Online) 학습으로 나누기도 합니다. 배치 학습은 학습시킬 데이터를 미리 준비한 뒤에 준비한 데이터를 학습시키는 방법입니다. 방법이 간단하다는 장점이 있지만 시스템이 빠르게 변화해야 하는 상황인 경우에는 사용하기 힘들다는 단점이 있습니다. 그리고 너무 학습 데이터가 너무 방대한 경우에는 시간이 지연되는 문제가 있기 때문에 점진적으로 학습하는 알고리즘을 사용합니다.
온라인 학습은 데이터를 미니 배치(Mini batch)라고 부르는 작은 단위로 묶은 뒤 이 데이터 셋을 학습시킵니다. 커다란 데이터셋을 다룰 수 있다는 장점이 있습니다.
Problems
다음은 머신러닝에서 발생하는 주요한 문제입니다. 머신러닝의 문제점 중 가장 많은 부분을 차지하는 것은 훈련 데이터입니다. 많은 데이터셋에 대하여 훈련 데이터의 양이 충분하지 않거나 대표성이 없고, 낮은 품질의 데이터인 경우가 많습니다. 또한 데이터셋 내에 관련 없는 특성이 많아 희소(Sparsity) 문제가 발생하기도 합니다.
과적합(Overfitting, 과대적합)과 과소적합(Underfitting)의 발생도 주요한 문제입니다. 과적합은 생성한 모델이 훈련 데이터에 너무 잘 맞아버려 일반화(Generalization)되지 않는 현상입니다. 과적합 문제를 해결하기 위해서는 파라미터가 적은 모델을 선택하기, 훈련 데이터에 있는 특성 수를 축소하기, 모델에 규제 적용하기 등의 방법을 통해 단순한 모델을 생성합니다. 과소적합은 너무 단순한 모델이 생성되어 데이터에 잘 맞지 않는 현상입니다. 과소적합 문제를 해결하기 위해서 파라미터가 많은 모델을 선택하거나 학습 알고리즘에 더 좋은 특성을 제공하고 모델의 제약을 줄임으로써 복잡한 모델을 생성합니다. 아래는 이미지의 왼쪽은 과소적합, 오른쪽은 과적합이 발생한 경우를 그림으로 나타낸 것입니다.
이미지 출처 : educative.io
과적합과 과소적합에 대한 추가적인 정보는 과적합과 과소적합 (Overfitting & Underfitting)에서 볼 수 있습니다.